ORIGINALLY, Weighted Gene Co-expression Network Analysis (WGCNA) was developed by Zhang and Horvath in 2005 for gene co-expression data. However, the researchers creating the approach quickly realized, that this method could also be helpful in other research areas and therefore renamed their method to “Weighted correlation network analysis”. Nevertheless, the WGCNA abbreviation is still widely used in literature. Lipotype scientists adapted that method for the lipidomic context.
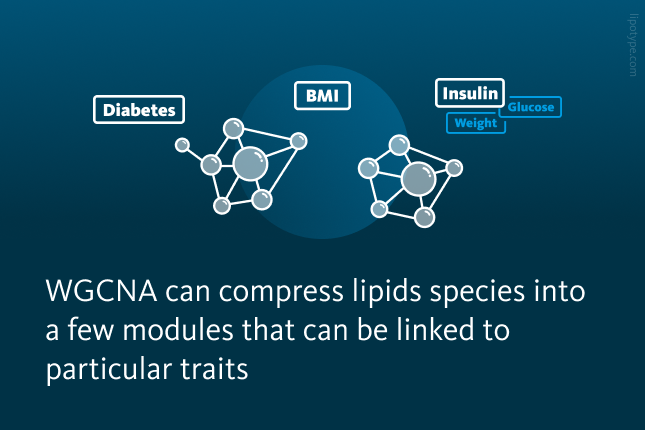
WGCNA can compress a huge number of lipids into a few modules, which can then be linked to clinical traits. High and significant correlations between the modules and clinical traits can be further explored to extract the property shared by all the lipids within that module that cause the effect.

The method helps to overcome the problem of applying too many statistical tests which often results in a high rate of erroneous test outcomes and manifests an increased rate of false positives or low statistical power, each of which has distinct implications for the accuracy of statistical analyses. Too many false positives means that too many statistical tests show significant results despite the absence of an actual effect. This can lead to misleading conclusions and wasting valuable resources by pursuing non-existent trends. On the other hand, efforts to control the false-positive rate may result in many genuine effects remaining undetected due to low statistical power. This way the risk of overlooking meaningful insights and potentially important findings within the data (low statistical power) increases.
WGCNA is a method that drastically reduces the number of statistical tests to be applied. In a nutshell, WGCNA in application to lipidomics data clusters highly correlated lipids into groups. These groups can then be related to external sample traits or outcomes, such as control vs. experiment. Instead of individually subjecting each measured lipid to a statistical test, WGCNA condenses the lipids into a small number of groups and then relates the groups instead of the lipids to an external trait. This way, the problem of too many false positives and low statistical power can be dealt with. Additionally, studying the properties of these groups can deliver valuable insights or potential biomarkers.
In the example data below, the extract from the data shows the mol percentage values of three lipids and how they are correlated.

A small lipidomic dataset and a table showing correlated lipid species. TAG 46:0;0 and TAG 46:1;0 are strongly correlated and CE 14:0;0 is only slightly correlated with the TAGs.
In this example, TAG 46:0;0 and TAG 46:1;0 are almost perfectly correlated and therefore it makes sense to put the lipid species in the same module (turquoise in the figure below). CE 14:0;0, on the other hand, is only slightly correlated with the other two and therefore belongs in a different module (yellow).
Instead of testing 161 lipid species in this example, we only work with five modules, where all the lipids in the same module are highly correlated to each other. The figure below shows the distribution of the lipids to the modules or groups. We can see that the majority of triglycerides (TAGs) are contained in the turquoise group. The dark red group instead consists mainly of phosphatidylglycerols (PGs).

The figure shows the different modules and their composition. Strongly correlated TAG 46:0;0 and TAG 46:1;0 from the small example dataset and are put in the same module (turquoise). CE 14:0;0 that is only slightly correlated with the TAGs belongs in a different module (yellow).
These modules can be related to the clinical trait. A two-group design with a control and a treatment (Experiment 1 and Experiment 2) group is presented in the next figure. Only moderate correlations between the trait variable (control/Experiment 1) and the modules can be observed. Importantly, none of these correlations are found to be statistically significant, as indicated by the adjusted p-values.
In contrast, a perfect and significant correlation of the turquoise module with the second trait variable (control/Experiment 2) is found while the blue and yellow modules are highly negatively correlated. These three modules can now be used to study the module properties, for example using the enrichment analysis.

Correlation values in the compared experimental groups. In brackets: raw p-value/adjusted p-value.
The table reveals the correlation between the modules and the corresponding trait variable. In brackets, the raw and adjusted p-values are displayed. The modules in Control vs. Experiment 1 show only moderate correlations with none being significant after p-value adjustment. Control vs. Experiment 2 instead shows perfectly high and significant correlations between the turquoise module and the trait variable and almost perfectly low between the blue and yellow modules and the trait variable. An enrichment analysis can now investigate the shared pattern in each of the three relevant modules.
All in all, WGCNA may be useful for compressing all the lipid species into a few modules, which are then related to a clinical trait. Highly correlated modules can be analyzed in more detail to gain a deeper understanding of the underlying mechanism causing the correlation. It is important to note, that imputation is required for analyses like WGCNA and OPLS-DA. But also, when you want to run statistical tests, as it allows you to include samples that have some missing data.



Lipotype Lipidomics technology offers an effective approach for those looking to gain a deeper understanding of lipid metabolism in both health and disease.
Need clarity on the process?
Ask us anything!

Lipotype products are provided for Research Use Only. They are not intended for clinical diagnostic purposes and must not be used to inform medical treatment decisions. The content of this article is for scientific and educational purposes only and should not be considered medical advice.